Software
Below is an overview of the software/API tools for the CANedge, CANsub, CANmod and CLX000 - all 100% free.

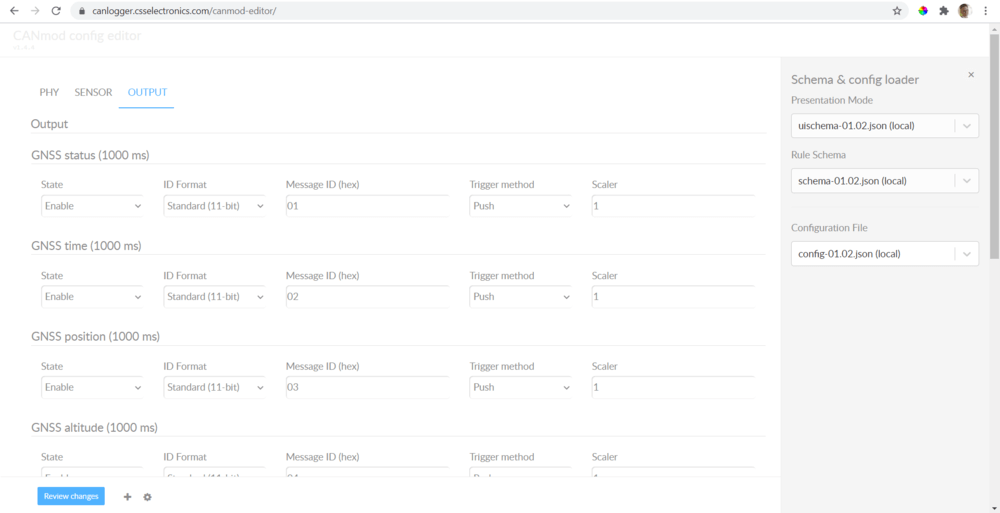
Configure your device
The config editor lets you easily load and edit your CANedge config - either offline or online.
intro playground open
Visualize via dashboards
Your CANedge data can be easily visualized in free, customizable browser dashboards - ideal for e.g. fleet telematics.
about playgroundManage devices & data
CANcloud is an IoT cockpit for managing your CANedge2/CANedge3 devices and data - e.g. via over-the-air updates and status dashboards.
about playground
Mount S3 server as drive
You can mount your S3 server as a 'local drive' - letting you e.g. process log files as if they were stored locally.
intro


Get your CAN logger/interface today - or contact us if questions!
FAQ
We believe that CAN bus software/API tools should be 100% free of charge. This means that you only pay for the hardware - which makes it far simpler to evaluate the total cost of a project. As a result, all software tools listed above are free, except for existing 3rd party tools like MATLAB and the S3 drive mounting tools.
A core design focus for the CANedge is on interoperability - making it easy for you to integrate the devices and data in existing software tools and systems. Below are a few examples:
- Configuration: The CANedge Configuration File uses the popular open 'JSON Schema' concept, meaning that you can use various open source 'schema editors' to modify and validate the Configuration Files. This is useful if you want to e.g. handle configuration of the devices in custom scripts or system integrations
- Log file format: The CANedge logs data in the standardized MF4 format, which lets you open the log files in various existing tools like asammdf. Our MF4 Python API also makes it easy to load and DBC decode the log files so that you can freely use the output in whatever integration you need
- Log file conversion: If the MF4 format is not suitable, we also provide our simple-to-use MF4 file converters - letting you quickly batch convert log files to e.g. CSV, Vector ASC or PEAK TRC
- S3 server interface: The CANedge2/CANedge3 pushes data to S3 servers, which is a modern form of object storage service. While originally designed by Amazon, it is today the most popular way of storing objects on servers - and it is widely supported across cloud servers (AWS, Google Cloud, Wasabi, DigitalOcean, ...) and free open source self-hosted servers like MinIO. Further, the powerful open source S3 API is available in all major languages (and is used in e.g. our CANcloud telematics platform)
We believe free open source software (FOSS) is the future:
- It enables collaboration and sharing of tools across a community of users that may exceed our direct customers
- It lets us leverage existing open source CAN bus software tools like asammdf and open source dashboard tools like Grafana
- Our end users can freely fork, modify, rebrand and commercialize the software, e.g. for use with their own customers
- Any bugs/issues/feature requests can be easily reported and handled via our github repositories
The CANedge2/CANedge3 lets you auto-push data to a cloud or self-hosted server.
We generally do not offer paid server/cloud hosting. Instead, we provide very simple step-by-step guides to allow you to set up your own server - with guides for each major server type. For example, you can set up an Amazon S3 server, Google cloud storage or Azure blop storage (with an S3 gateway). You can also self-host your S3 server using MinIO - either on a corporate server, virtual machine, local PC or even a Raspberry Pi.
By setting up your own server, you have 100% control over your data - and you avoid paying unnecessary subscription fees. It also allows you to freely switch server type - for example from a cloud server to self-hosted server. This way you reduce vendor lock-in.
To process your raw CAN or LIN data, you will typically need a DBC file (CAN database). This file contains information on how to decode the raw CAN data and extract relevant CAN signals like temperatures, engine speed etc.
A couple of scenarios exist when it comes to DBC files:
- If you're an OEM (Original Equipment Manufacturer), you will typically have a DBC file that you can use to decode your data
- If you need to log data from a car, you will typically record OBD2 data - and here you can use our free OBD2 DBC file
- If you log J1939 data from a truck or other heavy-duty vehicle, you typically need a J1939 DBC file, which we offer a license for
- If you need to log other types of CAN data, you may need to get a DBC from the OEM, find it online or reverse engineer the data
An important take away is this: In many cases, you will have direct/free access to the DBC file relevant to your use case. However, in some case - like J1939 data logging - you may need to purchase a DBC file. Think of the DBC file as a secondary input for use in the software/API tools, similar to how you load the log files you need to process.
If you're unsure about how to get the DBC file you need, feel free to contact us for sparring.
In some cases, you may want to process your data and send the output into some existing system - e.g. an SQL database, business intelligence system, data lake etc.
The CANedge is designed around making this process simple. For example, you can use our MF4 decoders to create a Parquet data lake with your data - which natively integrates with a wide variety of platforms, tools and databases. Alternatively, you can use our CAN bus Python API to load data from the CANedge (from local disk or an S3 server), DBC decode it to human-readable form and expose it in interoperable formats like pandas dataframes. Our telematics dashboard integration with Grafana provides a plug & play example showcasing how to integrate DBC decoded CAN/LIN data with a separate system.
For details on this, feel free to contact us.