CAN Bus Dashboards - Visualize Data Lakes [Grafana-BigQuery]

Need to visualize your CAN bus data in Grafana dashboards?
The CANedge lets you record 2 x CAN/LIN to an SD - and push it to your own server via WiFi/LTE.
In this intro, we explain how you can upload raw data to your Google Cloud Platform (GCP) bucket, DBC decode it via Cloud Functions - and visualize it via Grafana-BigQuery dashboards.
Tip: If you work in Amazon or Azure, see also our intros on Grafana-Athena or Grafana-Synapse dashboards.
Learn more below - and try our dashboard playground!


 CUSTOMIZABLE
CUSTOMIZABLE
Visualize your data in dynamic and customizable dashboards
 DATA LAKE
DATA LAKE
Data lake stored in GCP bucket - with database-like speed (but 95%+ cheaper)
 YEARS TO MS
YEARS TO MS
Navigate across years of data - and zoom in to the exact ms of interest
 SCALABLE
SCALABLE
Easily scale from 1 to 1000+ CANedge devices - and from MBs to TBs of data
 FREE & OPEN
FREE & OPEN
Grafana is 100% open source with a powerful cloud free tier
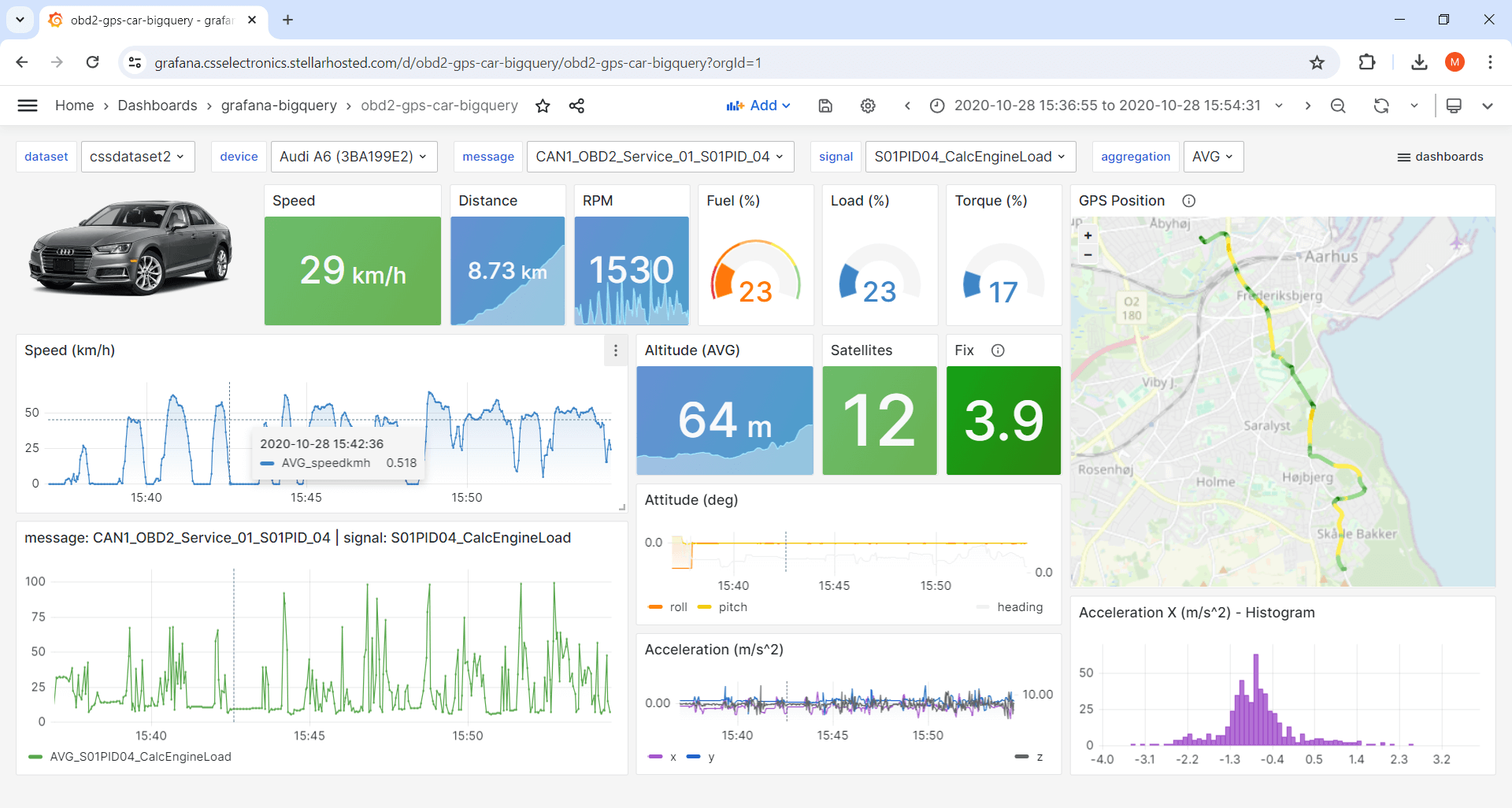
Open the dashboard playground - or deploy your own dashboard in < 15 min!
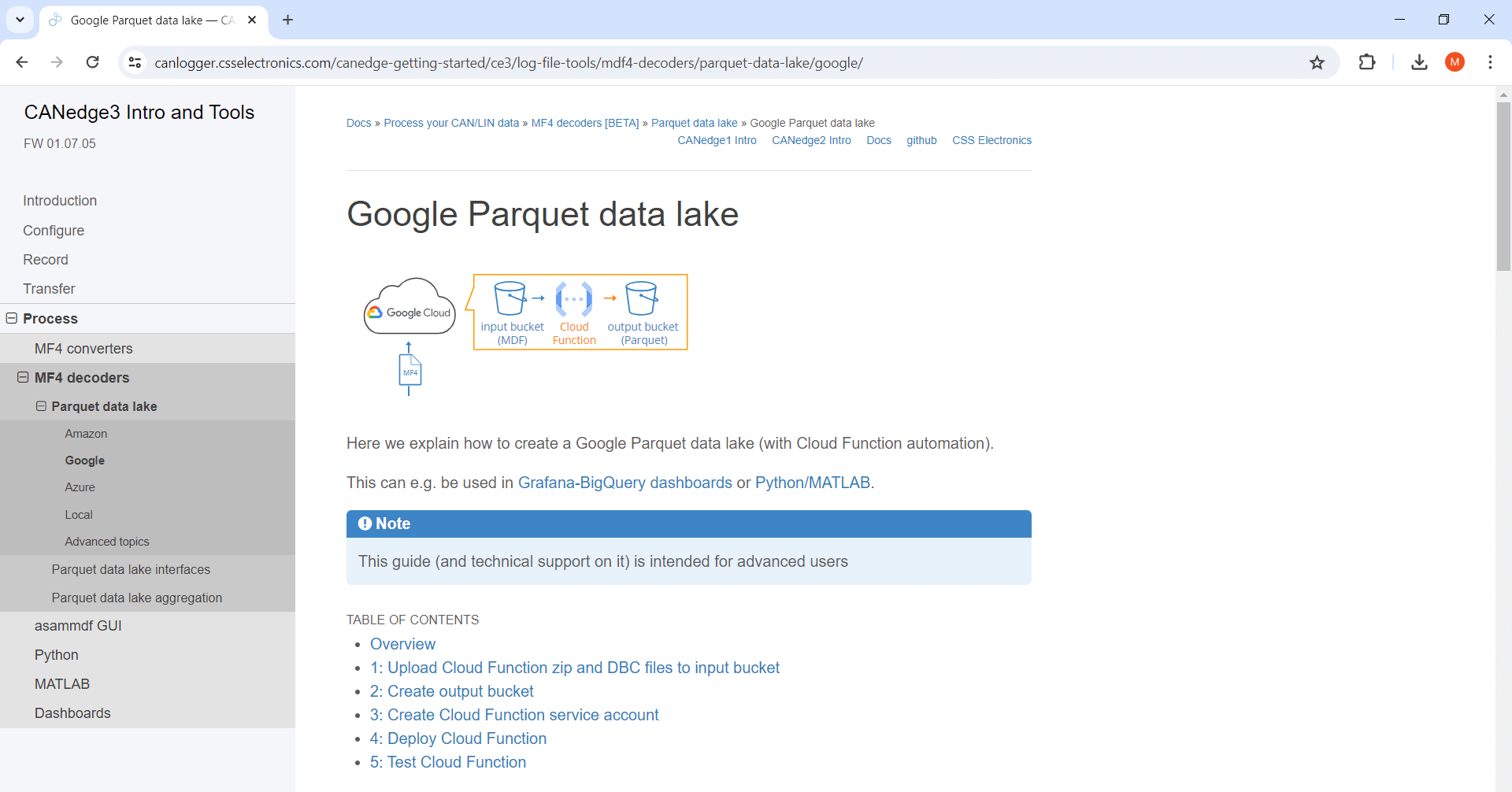
Grafana-BigQuery: How does the integration work?
Below we briefly explain a typical Grafana-BigQuery setup:
- A CANedge uploads raw CAN/LIN data to your 'input bucket'
- When a log file is uploaded it triggers a Cloud Function
- The Cloud Function DBC decodes the data to Parquet files
- The Parquet files are written to an 'output bucket'
- Grafana visualizes this 'data lake' via Google BigQuery
This can be deployed in <15 minutes - with zero coding.

Below we provide additional details on each core element of the integration.
Tip: You may also try our step-by-step integration guide with free MF4/DBC sample data now.
Cloud Function automation
Google Cloud Functions help automate the DBC decoding of new data:
- The Cloud Function runs every time a new log file is uploaded
- It loads relevant DBC files from your input bucket to decode the raw CAN/LIN data (using our MF4 decoders)
- The resulting Parquet files are written to an output bucket
- Cloud Functions are 100% serverless - you only pay when a log file is processed
- They are fully scalable, from 1 device to 1000+ devices
- All data processing is done automatically (and instantly) upon upload
Output bucket Parquet data lake
The output bucket stores your decoded data as a 'Parquet data lake':
- The data lake consists of Parquet files
- Parquet files are grouped by device, CAN message and year/month/day
- As a result, the data lake is compact and highly efficient
- The data lake is multi-purpose and can be used directly in e.g. Python/MATLAB
- Data lake storage is 95%+ cheaper than using a database
Example: InfluxDB Cloud storage cost is ~1.44$/GB/month vs. Google Cloud bucket storage cost of ~0.023$/GB/month.
Google BigQuery interface
Grafana can visualize your Parquet data lake by using the Google BigQuery plugin:
- BigQuery provides a simple SQL interface to Parquet data lakes stored in Google buckets
- Further, it can extract results from GBs of data in seconds via parallelization
- BigQuery is serverless - you only pay for the data scanned as a result of Grafana queries
- The cost of using BigQUery is extremely low at ~5$/TB (i.e. 1-10$/year for most use cases)
See also our Grafana-Athena intro for more details on why we recommend to use Parquet data lakes as the data source.
The CANedge2/CANedge3 enables you to upload recorded log files to your own server (self-hosted or cloud) - including Amazon, Google and Azure cloud. Dashboard visualization and Parquet data lakes are core tools for enabling CAN telematics at scale - and we therefore provide step-by-step integration guides for the top 3 clouds.
Below we briefly outline the three integrations:
Grafana-Athena: Most of our users connect their CANedge2/CANedge3 to Amazon S3, which is our default recommended cloud. Here, the Grafana-Athena integration can be used. It offers the simplest deployment, widest set of functionality (e.g. automated trip summary aggregation) and most efficient use of e.g. date partitioning. Data is uploaded to S3, automatically DBC decoded by a Lambda function and output to a Parquet data lake stored in another S3 bucket. This data lake is then queried via the Amazon Athena SQL interface - e.g. by Grafana.
Grafana-BigQuery: Google Cloud offers a nearly identical experience to Amazon as it provides a native 'S3 interoperability' functionality. Further, the Grafana-BigQuery dashboard integration is nearly 1:1 identical to Grafana-Athena. Uploaded data is automatically DBC decoded via Azure Functions and output to a Parquet data lake stored in another bucket. This data lake is then queried via the BigQuery SQL interface - e.g. by Grafana.
Grafana-Synapse: Azure does not provide a native S3 interface, but you can deploy an 'S3 gateway' (Flexify) to enable the CANedge to upload data to your Azure Blob Storage container. Uploaded data is automatically DBC decoded via Azure Functions and output to a Parquet data lake stored in another container. This data lake is then queried via the Synapse SQL interface. The data can then be visualized in Grafana using the Microsoft SQL Server data source.
Set up your own Grafana dashboard in <15 min
Use our step-by-step integration guide to set up your Grafana-BigQuery dashboard in minutes!
Create amazing CAN data visualizations
Visualize your data your way via beautiful graphs, synced GPS maps, gauges, tables, heatmaps, KPIs, histograms, pies, alert lists and more - anything is possible.
Customize your dashboard
Easily customize your Grafana dashboard panels including dark/light theme, chart colors, styles, pictures and logos.
Make your dashboards interactive (and scalable)
Enable users to interactively select devices and parameters via dropdowns to e.g. compare data patterns across assets.
Add event detection, notification & visualization
Identify custom signal-based events (e.g. high temperatures, active DTCs, ...), trigger email/SMS alerts - and visualize with event summary dashboards.
Aggregate data to trip summary statistics and visualize
Visualize customizable trip summary statistics across your entire fleet to enable powerful comparative analyses and browsing - with convenient cross-dashboard links.
Use Grafana Assistant to explore/visualize data
Leverage Grafana Assistant to analyze/visualize your CAN bus data lake with AI - and prompt your way to production-ready custom dashboards!
Collect 'big CAN data' from OEM prototype fleet
Need to visualize data from a fleet of vehicles?
You can deploy the CANedge2 or CANedge3 in a fleet of prototype vehicles to collect CAN data to your own Google Cloud account via WiFi or 3G/4G. Uploaded log files are automatically DBC decoded via Cloud Functions and written to your 'output bucket' Parquet data lake. From here, your engineers can visualize the data via customizable Grafana-BigQuery dashboards.


Visualize CAN/LIN data from your CANedge1
Want to visualize data that was recorded offline by CANedge1 devices?
The Grafana-BigQuery integration can be used even if you're logging data offline via the CANedge1. We provide plug & play Python scripts for DBC decoding and uploading a backlog of data from local disk to your Google Cloud output bucket. By following the Grafana-BigQuery setup guide, you'll be able to set up an output bucket for storing your data lake in a few clicks - and make it accessible for visualization in Grafana.
Build analytics platform towards your users
Need to create a white label dashboard solution for your customers?
The CANedge is designed for white labeling by OEMs and integrators. Add your own logo and use our tools to deploy tailored solutions for specific target audiences - e.g. for predictive maintenance, marine telematics, heavy-duty fleet management or OBD2 car telematics. As part of this, our Grafana-BigQuery integration makes it easy and low cost to deploy dashboards for specific use cases or clients.


Democratize your data lake via BigQuery SQL
Want to perform scripted analysis of your Parquet data lake?
Importantly, deploying a GCP Parquet data lake with BigQuery not only enables Grafana dashboard visualization. More generally, BigQuery provides a standard SQL interface to your entire data lake - enabling a far wider audience in your organization to work with your vehicle/machine data. For example, your team can perform SQL queries directly in BigQuery - or use e.g. Google Colab notebooks to quickly draft Python based data extractions. In particular, BigQuery eliminates the complexity that would normally be involved in extracting data from 'beyond-memory' datasets (e.g. 1 TB of data) - returning just the insights you want via simple SQL queries.
Ready to visualize your CAN data?
Get your CANedge today!


